
我校中医药人工智能学院唐文超团队联合构建中医药大语言模型性能测试基准“TCM-3CEval”
发布时间:2026.05.19点击:10
近日,我校中医药人工智能学院唐文超教授团队与上海人工智能实验室、中国中医科学院合作完成的研究成果“A triaxial benchmark for assessing responses from large language models in traditional Chinese medicine” 在Nature旗下期刊Communications Medicine上在线发表。该研究构建了中医药大语言模型性能测试基准——TCM-3CEval,为中医药与人工智能的深度融合提供关键评测工具。

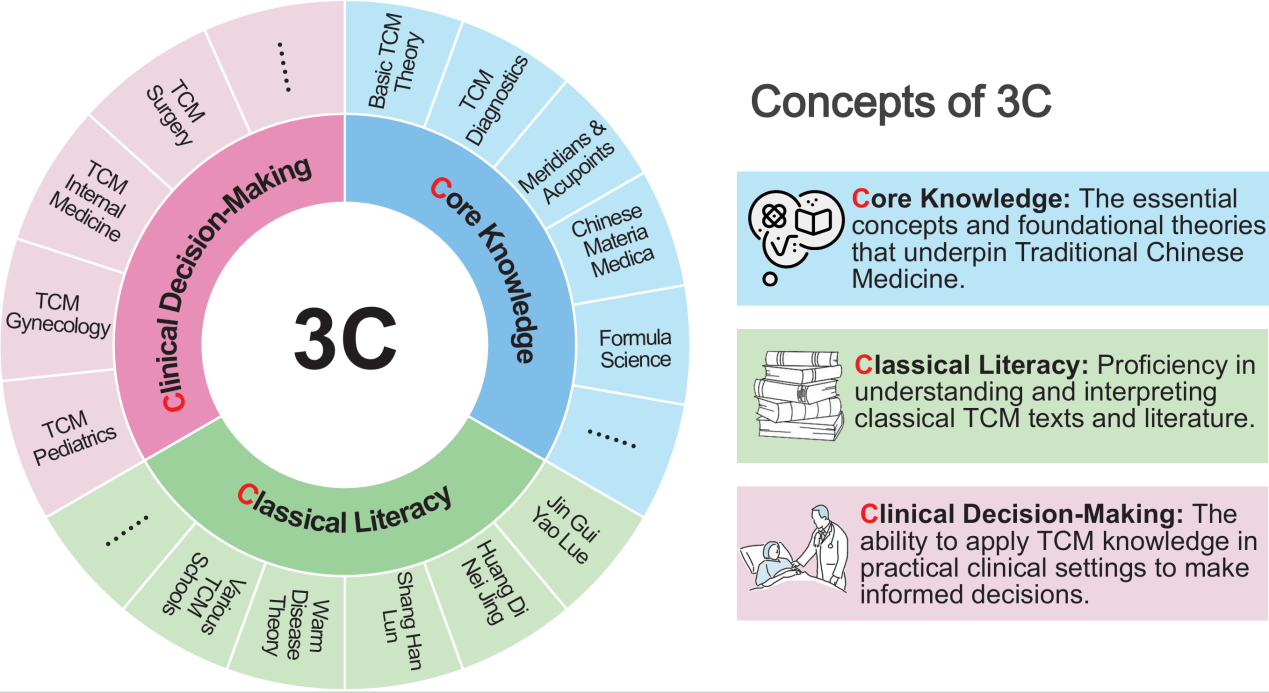
随着人工智能技术快速发展,大语言模型在通用医学领域展现出巨大潜力,但其在理论体系独特、临床实践复杂的中医药领域,长期缺乏系统、多维度的评估标准。针对这一空白,研究团队构建了全国首个通过严格同行评审并完成信度、效度检验的中医药大语言模型性能测试基准——TCM-3CEval。该基准基于中医药人才能力培养路径,包含“基础知识掌握、经典文本理解、临床决策评估”三个维度。
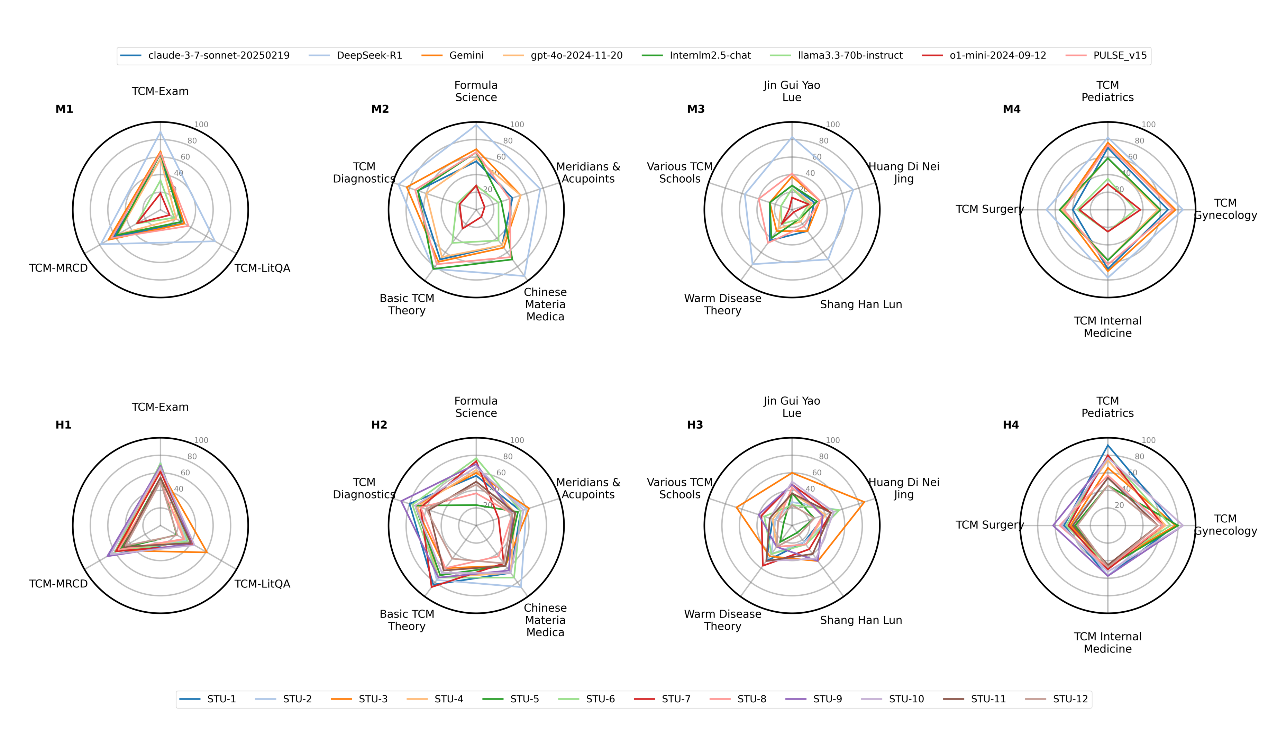
基准共包含450个经多轮专家验证的标准化测试项目,采用选项排列一致性检验消除位置偏倚,并评估了8种主流大语言模型。此外,团队还引入中医药研究生进行人机对比,结果发现,模型在临床决策维度上的整体表现与人类相当(56.1% vs. 57.9%),但在中医诊断学、证候鉴别等需要辨证推理的子维度上显著落后(如诊断学61.7% vs. 71.4%),暴露出AI模拟中医整体性临床思维的局限。而在经典文本理解任务中,具有中文文化先验的模型(如DeepSeek-R1)准确率达71.8%,远超国际通用模型(12.1%),凸显了文化语境对齐的关键意义。TCM-3CEval能够有效区分机械记忆与真实临床推理能力,表明当前模型虽在结构化知识上表现不俗,但面对中医独特的辨证论治体系,仍需在文化适配与整体性推理建模上实现更深层次的突破。
我校中医药人工智能学院为论文第一完成单位,我校中医药人工智能学院研究生黄天爱和上海人工智能实验室高级工程师陆路为论文共同第一作者,中国中医科学院赵宇平研究员、我校中医药人工智能学院唐文超教授和上海人工智能实验室徐捷研究员为共同通讯作者。该研究得到国家自然科学基金及上海市卫健委、中管局等课题资助,是医工交叉协同创新的重要成果。目前TCM-3CEval基准已在Medbench中医药评测赛道(https://medbench.opencompass.org.cn/track)上线,接受各大中医药大语言模型研发机构进行开放化测试。未来,团队将持续完善评测基准,推动中医药AI从“技术适配”走向“体系融合”,为人工智能赋能中医药现代化提供方法论支撑。(科技处、中医药人工智能学院)

